Interpretability in Data-Centric ML
Introduction to Interpretable ML
Interpretability is the degree to which a human can understand the cause of a decision of an ML model.
Interpretability is important for three reasons:
- Debugging a model to improve performance and validating that the model will perform correctly in the real world.
- Reviewing incorrect decisions that were made after deployment
- Improving usability of models when being actively used by decision-makers.
Why do we care about interpretable features?
Consider the following examples of explanations on the California Housing Dataset. In this dataset, each row represents one block of houses in California. Our goal is to use ML models to predict the median house price of houses in each block.
Take a look at the image below, which visualizes a decision tree model trained for this purpose. Decision trees are usually considered very interpretable models, because you can follow their logic through a series of simple yes/no questions. Do you feel like this visualization offers you anything towards understanding how the model makes predictions about house prices?
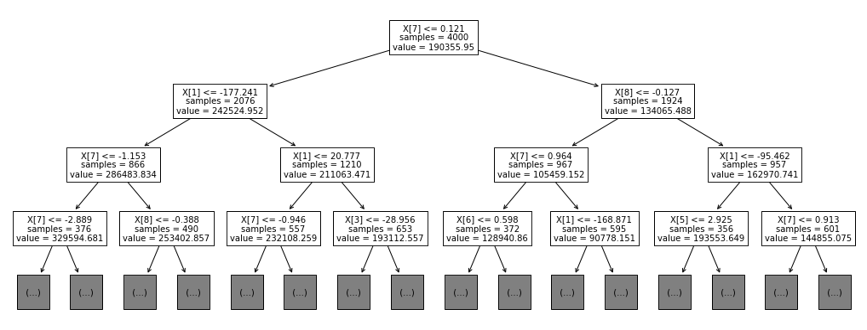
The visualization above displays features generated from running a principal component analysis on the original feature set. This is a powerful algorithm that reduces the size of a feature space and can improve generalizability of models, but also reduces the interpretability of their features.
Next, consider the two images below, both offering feature importance explanations of models trained on the California Housing Dataset. The first was trained on a set of automatically engineered features, while the second uses the basic features that come with the dataset. Both models have similar performance (r2 ~ 0.85), but you may find the second explanation much easier to reason about.
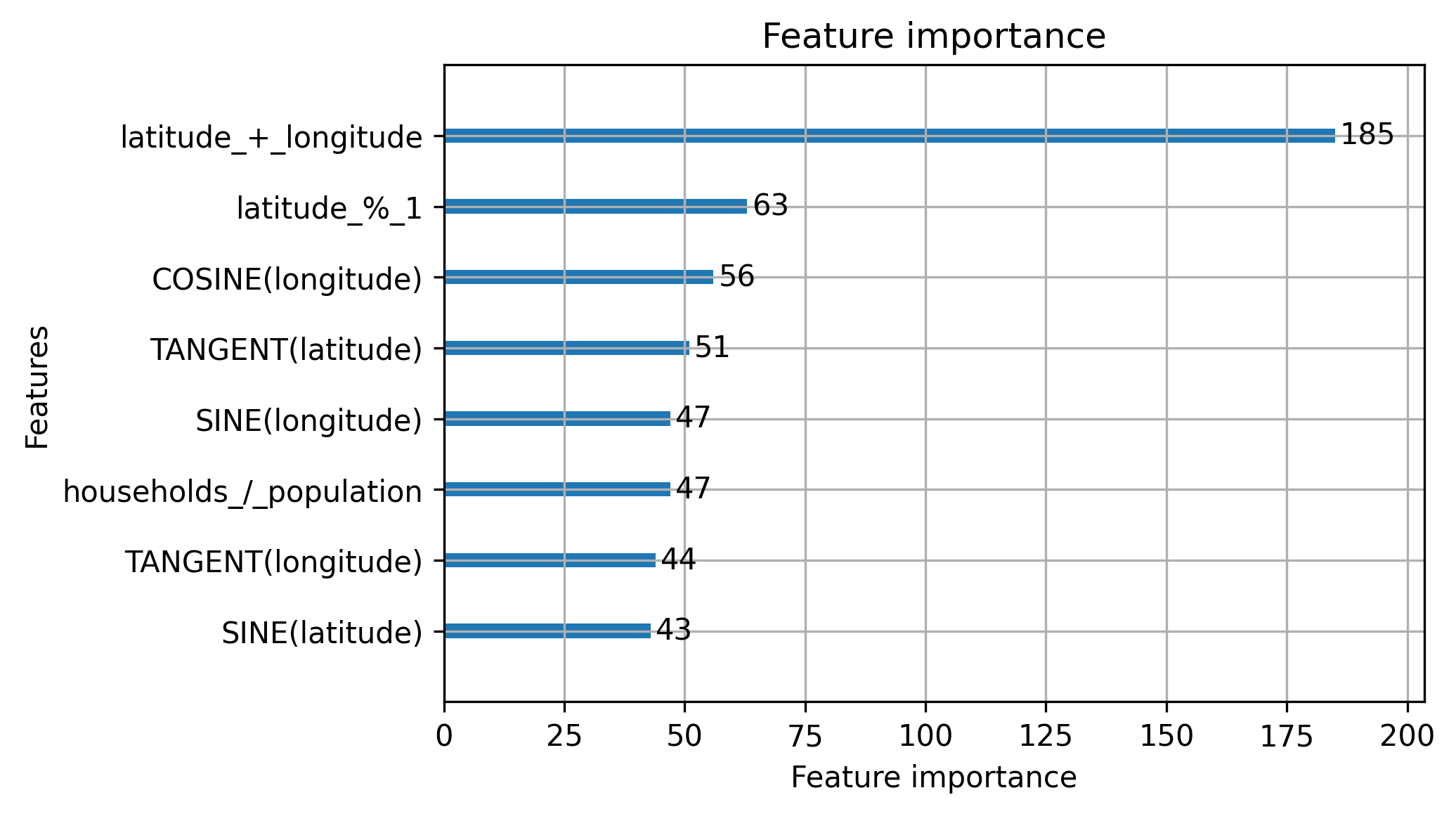
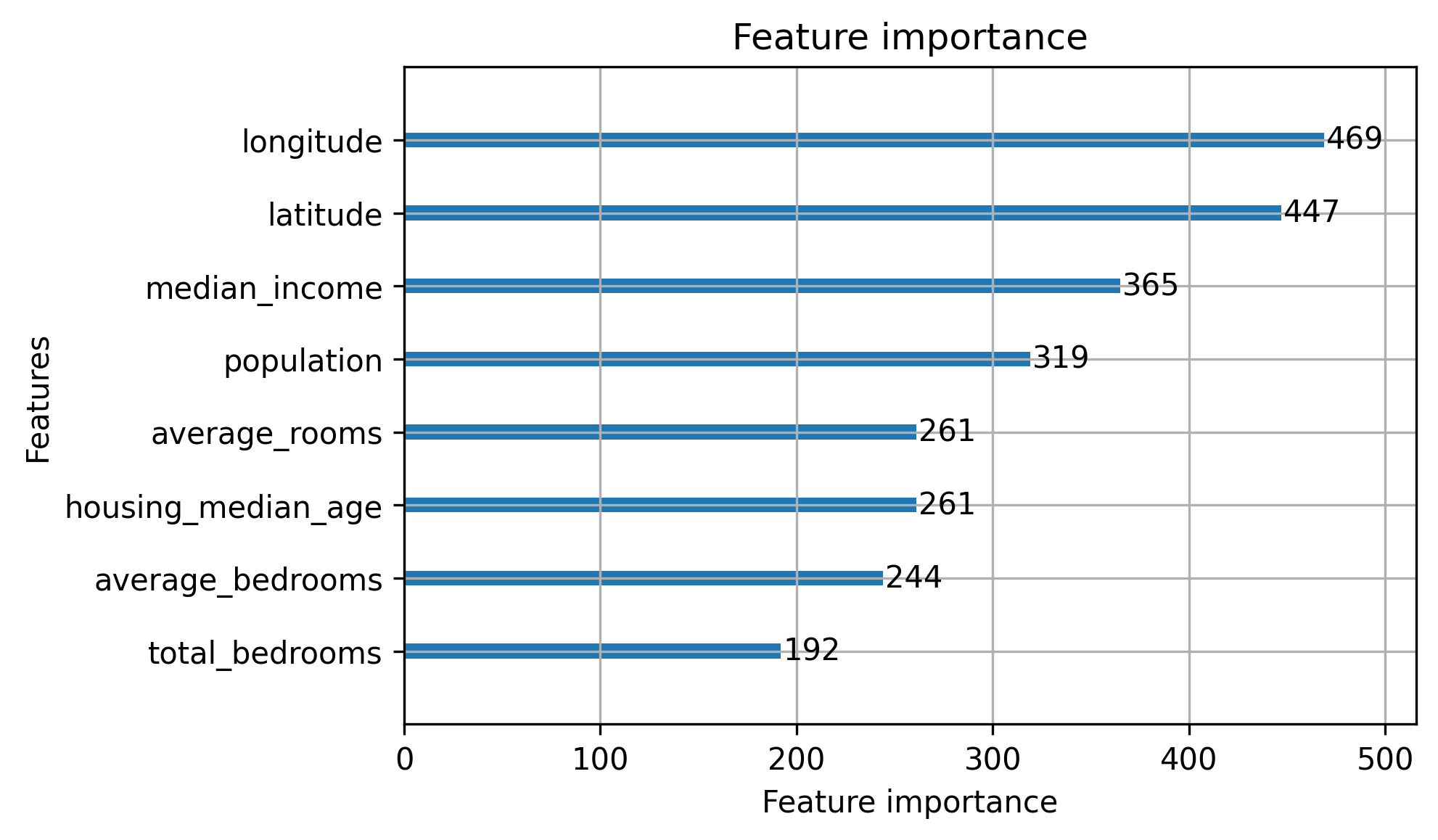
Performance and Interpretability
You may have heard of (or assumed the existance of) a “performance/interpretability tradeoff”. In other words, as you modify your features to be more interpretable, you might expect the performance of your model to decrease. In theory, this is a logical assumption - how could adding additional constraints on your feature space not result in a performance reduction?
In reality, we don’t have access to infinite resources or data — we can’t try every possible configuration of data. When we look at how machine learning behaves on real-world examples, we see that adding interpretability to features and models actually tends to lead to more efficient training, better generalization, and fewer adversarial examples (Rudin, 2018, Ilyas et al., 2019).
Having interpretable features ensures that our model is using information that we know is relevant to our target, thus reducing the chance of the model picking up on spurious correlations.
In the situations where we do see a performance/interpretability trade-off, it’s up to you — the ML engineer — to consider the domain at hand to understand the relative importance of performance vs. interpretability, which changes from case-to-case.
What are interpretable features really
Interpretable features are those that are most useful and meaningful to the user (i.e., whoever will be using the explanations). Unfortunately, what this means varies heavily between user groups and domains.
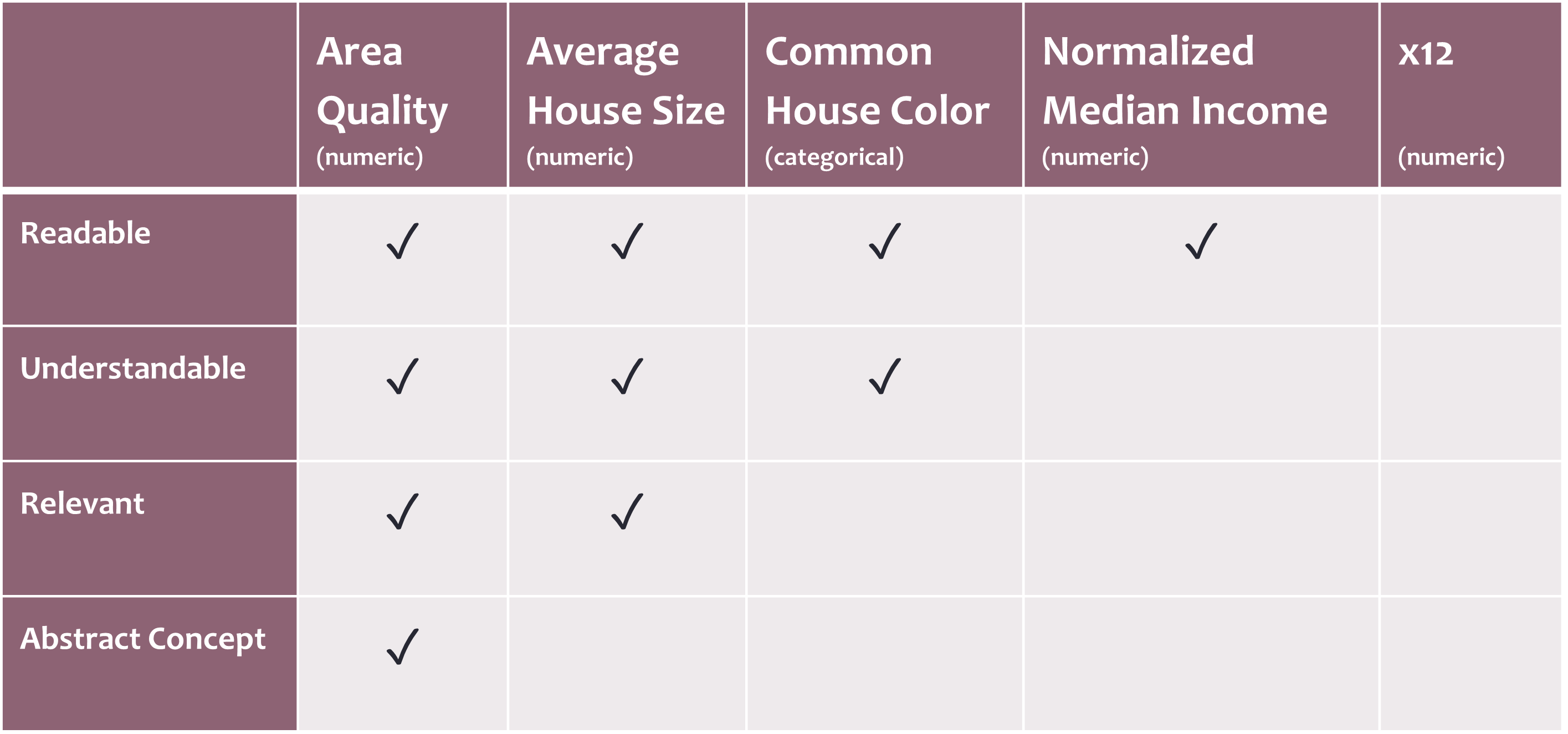
There are many properties that relate to feature interpretability (Zytek et al., 2022). A few to consider include:
- Readability: Do users understand what the feature refers to at all? Codes like
X1are not readable, and should be replaced with natural-language descriptions. - Understandability: Can your users reason about the feature value? It’s often easier to reason directly about real-world values than values that have been standardized or otherwise engineered. For example, thinking about income in direct dollar values (
$50,000) is easier than thinking about a normalized measure of income (.67). - Meaningfulness/Relevancy: Users have an easier time trusting, and are therefore more likely to use, models that use information that they believe is important.
- Abstract Concepts: Depending on your user-base and their expertise, it may be valuable to condense features into digestible abstract concepts — for example, combine detailed information about the area into a single metric of “neighborhood quality”. There is a tradeoff here — using abstract concepts can (sometimes nefariously) hide important information.
The table below shows some examples of features and their properties.
How do we get interpretable features?
[Feature engineering] is the first step to making an interpretable model, even if we don’t have any model yet (Hong et al., 2020)
There are three main approaches to interpretable feature generation:
- Including users (or at least humans of some kind) in the feature generation process
- Transforming explanations separate from data
- Using automated feature generation algorithms that factor in interpretability
Including the User
Traditionally in design tasks, users are included through the iterative design process. In short: include your users in every step of the process (including feature engineering!) and iterate based on their feedback.
There are ways to make including the user in feature engineering easier, such as through collaborative feature engineering — systems that allow multiple people to easily collaborate in feature generation.
In this lecture, we introduce two systems for Collaborative Feature Engineering — Flock and Ballet.
Flock:[^4] Flock takes advantange of the fact that people have an easier time highlighting important features when comparing and contrasting, rather than just describing. To this end, Flock shows users (“the crowd”) two instances of different examples from the database, and asks them to 1) classify them and 2) describe in natural language why they chose their classification. These natural language sentences are then separated into phrases by conjunctions and clustered. Finally, these clusters are once again shown to the crowd to be labelled.
Let’s walk through an example, where our task is to differeniate paintings by two artistis with similar styles: Monet versus Sisley.
- Show users one painting by each artist, and ask them to identify which artist they believe painted each:

- Ask for a natural-language description of why they chose their classification:
The first painting is probably a Monet because it has lilies in it, and looks like Monet’s style. The second probably isn’t Monet because Monet doesn’t normally put people in his paintings.
- Split up the description at conjuctions (and/or) and punctuation, and cluster the resulting phrases:
The first painting is probably a Monet because it has lilies in it
It has flowers
The painting includes lilies
There are flowers and lilies in the painting
- Show users the clusters and ask for a single question that would represent the cluser:
Does the painting have flowers/lilies in it?
These questions represent crowd-generated features, that should be very interpretable because they directly represent the information users used to classify the instances.
Features generated by Flock have been shown to improve performance over using raw data directly, using machine-generated features, and using only human classification.
Ballet (Smith et al., 2020): Ballet is a collaborative feature engineering system that abstracts away most of the ML training pipeline to allow users to focus only on feature engineering. With Ballet, users write just enough Python code to generate a feature from a dataset. These features are then incorporated into the feature engineering pipeline and evaluated.
Explanation Transforms
To generate more interpretable features even in situations where models require some degree of uninterpretability in their features (for example, models often require standardization, one-hot encoding, and imputing data), we can apply post-processing transformations to the explanations themselves. One tool that helps with this is Pyreal.
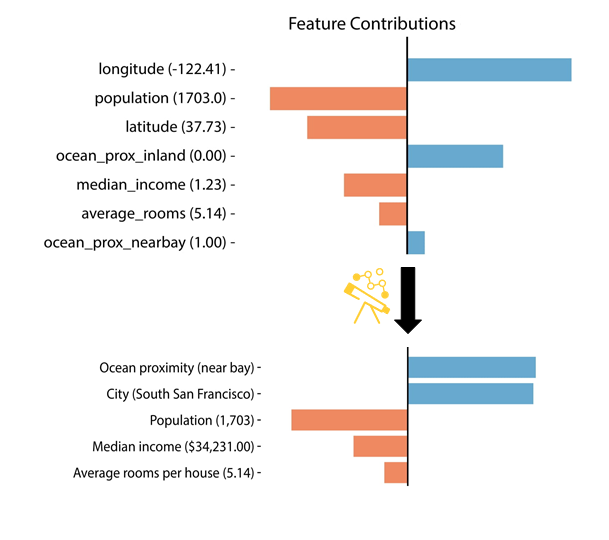
Pyreal automatically “undoes” data transformations that reduce the interpretability of features at the explanation level, as well as adding additional transformations that can improve the interpretability of features in explanations. For example, consider the image below, showing an explanation before and after being transformed by Pyreal. In particular, notice that one-hot encoded features are combined into a single categorical feature (ocean proximity), less interpretable features are transformed to more readable versions (lat/long -> city), and features are unstandardized (median income).
Interpretable Feature Generation
Some automated feature engineering algorithms are especially formulated to generate more interpretable features. These algorithms often consider things like what information is most contrastive, meaning it specifically separates classes, or focus on reducing the feature number to a more easily parsable subset.
One example of such an algorithm is the Mind the Gap (MTG) algorithm (Kim et al., 2015). This algorithm aims to reduce a set of boolean features to a smaller, interpretable subset.
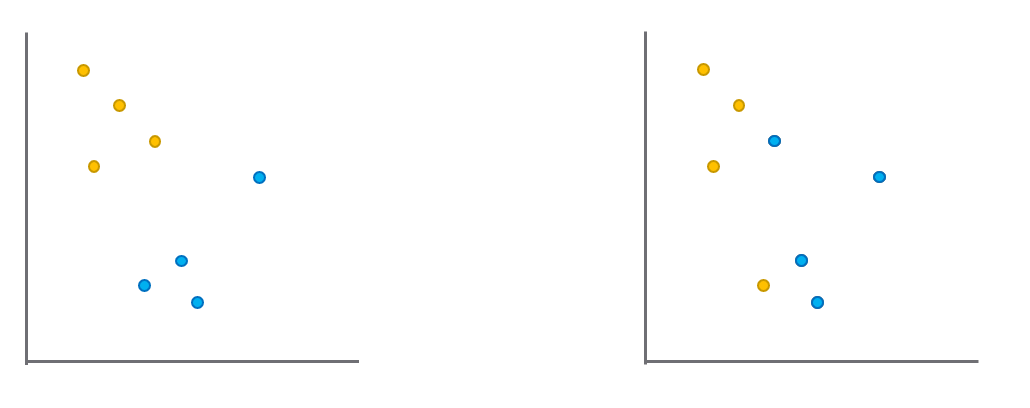
MTG begins by randomly assigning features to “feature groups”, defined by one or more features concatenated with “AND” or “OR”. It then determines which of these groups results in the largest “gap” between true and false instances, and iterates. For example, in the image below, the yellow and blue dots represent instances that are True or False for a given feature group. Here, the left feature group results in a bigger gap than the right feature group. Through this process, MTG creates a small set of features that maximally separate classes.
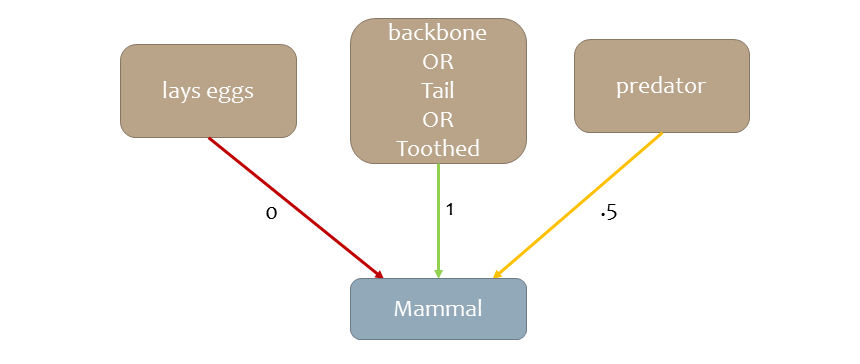
And here are some examples of the kinds of feature groups we could generate using MTG. For a specific set of values for each of these groups, we get a cluster that we could describe as “mammals”.
Conclusion
The key takeaways from this lecture:
- If you care about the interpretability of your machine learning, you should also care about the interpretability of your features.
- Features are interpretable if they are useful and meaningful to your users — different users have different needs.
- You can generate interpretable features by including humans (ideally, your users) in the feature generation process. You can also transform the explanation itself, or generate features using an algorithm that considers interpretability.
Lab
The lab assignments for the course are available in the dcai-lab repository.
Remember to run a git pull before doing every lab, to make sure you have the latest version of the labs.
The lab assignment for this class is in interpretable_features/Lab - Interpretable Features.ipynb. This lab guides you through finding issues in a dataset’s features by applying interpretability techniques.
Licensed under CC BY-NC-SA.